This the third episode of Natural Prodcast, and the third and final part of our Primer conversation, where we’ve introduced concepts in natural products and secondary metabolism. Revisit part 1 here and part 2 here.
You can find the podcast on Apple, Google, Spotify, Stitcher, directly with the RSS link, and via most other commonly-used podcast feeds. Please subscribe, and leave a review!
If you have questions or comments, you can contact us on Twitter at @JGI or @danudwary, or by email to jgi-comms@lbl.gov. We’d love to get your feedback!
Transcript of episode 3
DAN: You’re listening to the US Department of Energy Joint Genome Institute’s “Natural Prodcast,” a podcast about the science and scientists of secondary metabolism.
DAN: Hey there. This is Dan again, and you’re about to listen to the 3rd and final part of Natural Prodcast’s “Primer” episodes. This IS the third part, so if this is the first episode you’re checking out, you probably want to go back and listen to the first two parts (part 1 is here and part 2 is here) so you understand what’s happened so far in the conversation between me and Alison. In the previous episodes we talked about the basic science and the history of the field of natural products or secondary metabolism, depending on which term you prefer. In this episode we’re going to finish up by talking about the modern, post-golden age history of natural products discovery, and we’ll talk a lot about the current state of things, and what we’re hoping to accomplish at JGI in this area.
If this series of podcast episodes has sparked your interest, and you want to learn more, then I highly recommend David Hopwood’s book called “Streptomyces in Nature and Medicine.” It’s obviously focused more on the bacterial side of the field, and it’s a little hard to find in print, but we live in the information age and the ebook version is available at most online sellers. I think it’s as accessible as anything in this field, and written pretty close to the level of technical detail that I think we’re doing here. If you have suggestions for others feel free to let me know by emailing jgi-comms@lbl.gov, or reaching out on Twitter to @JGI or me @danudwary.
Like I said in the intro to the first episode, after this we’re going to be spending some time talking some great scientists, who all have really interesting stories and very cool research. I hope you’ll stick around. But, for now, here’s episode 3 of the Primer!
—
DAN: So, you know, in the in the 50s 60s 70s, most of the exploration of this is done by what’s called “find and grind”. So you would find some new source that you hadn’t explored before. Like, you know, maybe it’s a new culture of a new bacteria that you pulled from the soil, maybe it’s, you know, we talked about sponges, go pull a sponge or extract some tree bark. And so you’re just taking something, you’re grinding it up, and then exposing that extract to something that you want to try to target. So if you’re trying to find an antibiotic, then you expose bacteria to your extract and hopefully, if you see the bacteria dying, then you know you’ve got an antibiotic that might be useful. And so that was great for a while, but it’s not everything. So, finding new sources is somewhat problematic. And there’s a whole process to this, that can be really time consuming because you need to, you know, produce first an extract of the thing that you’re doing. And you know, that’s not too hard. But then you need to test it. Some testing might be hard, depending on how you’re doing the testing. If you have a successful test, then you need to go back to your extract and try to purify the molecule that’s causing that test to be successful. Right? Because we don’t – drugs are usually single molecules, they are not extracts. And so yeah, in order to sell a drug, you usually need a pure compound, to understand intimately what that’s doing. So you know it’s not doing harm and there aren’t side effects.
ALISON: Yeah, I guess you’d use something like a gas chromatographer. Yeah.
DAN: Yeah. So that involves figuring out the structure of that pure molecule. And that can that can take a long time depending on how the purification goes. In order to be a drug, you also nowadays usually need to know what the target of the drug is. What is the drug actually hitting in the body? And what effects is it causing? That’s a very long process. And then finally, if all of that still works, and you have a good target and a good drug, and something that’s easy to access, and you can still make more of it, then you start going into human trials or animal trials first, and going through all those trials is, you know, a very long, very expensive process. And so, drug companies really needed ways to kind of short-circuit that, and natural products wasn’t necessarily cutting it. They had this you know, big curve of lots of new molecules being discovered lots of new things making it to market and they wanted to keep that trend the same. But as you see, the number of new natural product molecules was starting to decline around the 70s. It’s really very, very low these days. So maybe one or two or three natural product molecules might actually get to market in a year. And that would be a good thing. That would be high.
ALISON: I mean, I’ve heard some statistic about how few antibiotics, I think, have been introduced after this golden age. I can’t remember exactly what the number was. But I want to say it was like less than 10. Since, you know, a recent decade.
DAN: I’m sure that’s right.
Dan [post-edit]: Hey, Dan here. Just going to interject. Alison asked me to check her stat and she was absolutely correct. Since 2010 there have been eight new antibiotics added to the market. And we get to say that six of those are based on natural product structures.
DAN: One of the things that keeps me awake at night, worried about my kids’ future is actually the number of antibiotics that we are not finding. We are going to have more resistant bacteria. There are lots of resistant bacteria out there and some really bad infections that are killing more and more people and we need more antibiotics to combat those. We’re not doing enough to do that. There are lots of reasons for that, mainly economic but … Yeah. But natural products would be still be a good source for that.
So yeah, and in order to keep this drug discovery train moving, drug companies started working with some techniques referred to as “combinatorial chemistry”. And so if you can picture, some really simple chemical reactions where you’re just putting two units together in a foolproof way, then if you imagine, say, if you had three pieces like an A, B and a C, you can make ABC very, very easily just by combining A and B and B and C, and you’ve got a new molecule, right? And so if you have 1000 A’s and 1000 B’s and 1000 C’s, then if you’ve got a robot that can do it all you can make a billion molecules in an afternoon. And so it was thought that combinatorial chemistry, learning some of the lessons from natural products, in terms of what kinds of chemical scaffolds you might want – it was thought that that would be a good substitute for the long process of natural products-based discovery. Not the case, as you say, not too many new drugs making it to market, still.
ALISON: Yeah, so that was a lot of like synthetic chemistry effort to create a bunch of novel compounds that actually didn’t pan out.
DAN: And there are some successes, but not as many as there were natural product hits. Sort of in parallel with that, the field of molecular biology got more sophisticated around the 80s and the 90s. And so we started to be able to explore DNA sequencing and actually get to the DNA sequence – sequences for the genes that code for the proteins that produce secondary metabolites. Do you recognize this?
DNA 🡺 RNA 🡺 Protein
ALISON: This is central dogma. DNA to RNA to protein.
DAN: Yeah, this is the central dogma of molecular biology. And so DNA makes RNA makes protein. Something that’s you know …
ALISON: Central!
DAN: That’s why they called it that! But for, maybe, people who are less familiar with central dogmas of molecular biology, DNA is the storage medium for information in ourselves and every living thing that we know of with cells, and so… So you can think of DNA as maybe being similar to – I used to use a computer analogy when I was teaching it to people who are outside the field. So DNA might be the installation disk you get for your software. A CD ROM.
ALISON: I feel like you’re dating yourself. CD ROM…
DAN: Maybe DNA is the you know, the git repository for your software.
ALISON: There we go. Okay.
DAN: So DNA is transcribed into RNA in the cell. That’s the “message” that comes from the DNA. It’s the precursor to Protein. Protein is then translated from RNA.
ALISON: Okay, so in your computer analogy, though…
DAN: So then RNA might be the software after it’s been installed on your hard drive. And then the protein would be the software actually running in your computer’s memory. So it’s there and doing things.
ALISON: Right. Yeah.
DAN: Alright, so a subset of proteins are enzymes. Enzymes are proteins that do chemical reactions. And so secondary metabolites come from reactions, of enzymes and sometimes those are referred to as “small molecules” because proteins are actually molecules too, right? And so in a biological context, natural products and primary metabolites are going to be small molecules. And so, the reason I bring this up is because, you know, as the technology developed and molecular biology developed to the point that you could understand the genetics of secondary metabolism, it became possible to do something that the field refers to as “genome mining”. So, if you can sequence the DNA and actually recognize what’s going on in the DNA, you can make predictions about what kinds of proteins exist in a cell and identify those proteins that are enzymes that are doing the reactions to generate secondary metabolites.
ALISON: Sounds easy enough?
DAN: Well, it is and it isn’t. It depends on different systems of secondary metabolism and the things that are in there. So once you could sequence DNA, then it was just a matter of time before some secondary metabolism gets sequenced right? You know, it took some time to get to the point of being able to sequence whole organisms, but eventually we got there. But before that there had been lots of exploration of the genes that would encode secondary metabolism. People wanted to understand what those were and how related they were to primary metabolism, and, as we discussed, they are very related. They are, you know, duplications and modifications. But one of the fun things that came out of investigating those genes is that it was found that most biosynthetic genes are found clustered in the DNA. And so if you can identify a gene that’s likely to be involved in secondary metabolism – production, say of a certain molecule. If you can find one of those genes, often you can find all of the genes. So that’s one of the real utilities for genome mining is you can identify biosynthetic gene clusters relatively easily. And if you can do that, and you can look at the patterns in the genes and all of the details in that sequence, then you start to recognize patterns. And you recognize that secondary metabolism, you know, is also duplicated itself. And so there’s, you know, we’ve already said secondary metabolism is everywhere. But it turns out secondary metabolism systems are also everywhere – that there are some very specific patterns and shared DNA across all of these things. It turns out secondary metabolism is very, very ancient and has been shared for a long time by many, many bacteria – and fungi and plants. And so that’s the power and the promise of, I guess, the current age of secondary metabolism is that it’s very DNA-driven. Sequence-driven. Yeah, because we can find more things. Turns out some of the early genomes that were sequenced for, say, Streptomyces – they found far more secondary metabolism genes than they were expecting to. So you might know of like three or four or five molecules that you maybe had found and ground from your cultures, but then you’re going to find another 20 or 30 secondary metabolism pathways that you didn’t even know existed. And so, that gives you another way to, you know, if you know what to look for, you might know something about how to turn it on, and how to how to actually get the molecules to be produced by the thing. Sometimes. When we grow things in the lab, we’re not growing them in their natural environment, we’re not subjecting them to the environmental triggers that they might need to turn a pathway on. But now that we have more technology, we can start to modify that and maybe tinker with the organism’s DNA itself to be able to do that.
ALISON: Yeah, so the power and the promise, and that’s the age that we’re living in now?
DAN: Yeah, I think that’s probably where we are today.
ALISON: So where are we today, Dan?
DAN: Well, today, I think we’re more or less in the same place we’ve probably been since the last decade. We have a lot more data. Obviously, there’s been a lot of sequencing going on, especially at the JGI and in other places. And we have many, many 10s – or probably at this point millions of biosynthetic gene clusters.
ALISON: Oh my gosh, millions. That’s incredible.
DAN: So they’re out there, but we don’t have millions of molecules. In an ideal world, knowing that something can be produced, you know, you would be able to find it. But it turns out, you know, like we said, that whole process of isolating molecules and purifying them from, you know, natural sources or natural cultures, sometimes it’s very hard. And it’s still not something that we’ve completely been able to tackle. And so –
ALISON: So I do want to interject from a more molecular biology perspective, like if you have a cluster of genes, why can’t you just engineer you know, a promoter or an enhancer, an activator, to go ahead and, and synthesize those genes within a model organism like E.coli, and have it produce the compounds so that you can test them?
DAN: Yeah, sometimes you can. Sometimes you can do that. And that’s great when you can. But there are lots of times where you can’t. So imagine if you had a sequence from a bacterium that maybe you had never cultured, that you took a sample from a sponge and you had this sequence, you know that there’s a really interesting gene cluster, but you don’t have that organism in a tube, you don’t have the ability to grow that thing. So all you have is the DNA. And so, in order to access that, probably what you need to do is synthetic biology. That’s synthesizing the DNA that would be coding for that pathway and putting that into an organism. But some of those pathways might not be tractable to synthesis. So synthesis is still very expensive and very difficult. And it turns out some types of natural product pathways are really difficult to synthesize. So we’ve got a picture up here of the erythromycin polyketide synthase.
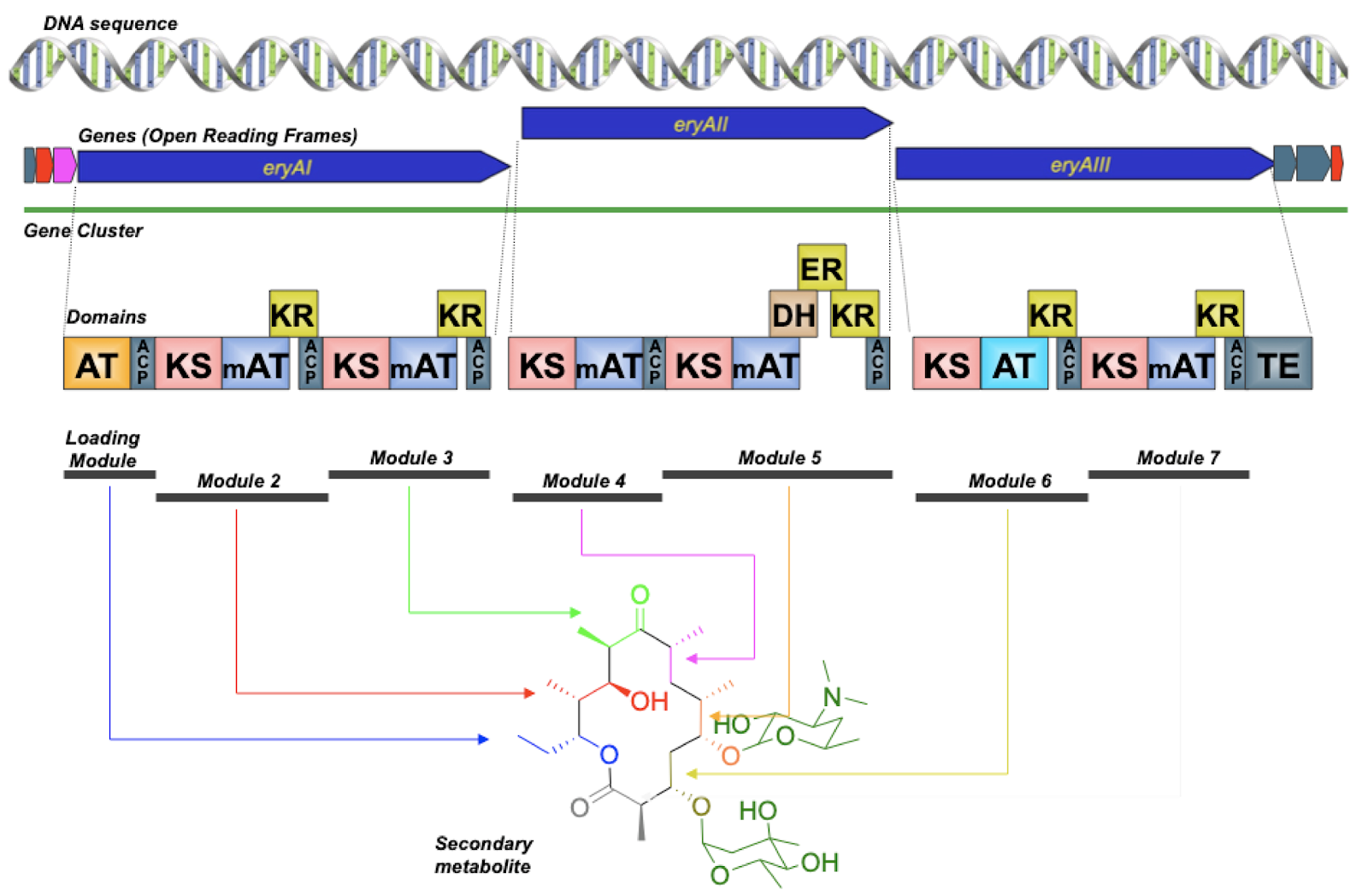
DAN: And, so, you don’t need to know what all this is. But if you look at those little squares on the bottom, those squares are depictions of what are called domains within a larger protein. And so each of those domains is sort of like a small protein itself. Some of them are actually pretty large. But this particular kind of biosynthetic pathway are these really, really large proteins that are basically beads on a string of smaller proteins all strung together. And this thing, the biosynthesis that happens here is really, really interesting in terms of – well it’s really simple in terms of understanding it because it’s an assembly line. You just go down the string of beads and each bead is doing a chemical reaction. And then the final product is released. And you’ve got this molecule called erythromycin, which is a common antibiotic.
ALISON: Yeah, Ford would be very proud.
DAN: Yeah. But it turns out that if you wanted to say synthesize this thing… Do you notice anything in particular about those squares? Those domains?
ALISON: Well, so they are – there are a few things. So they’re repeated. And they’re repeated in a similar order, which I could imagine would be difficult for a sequencer.
DAN: That’s right.
ALISON: Or for sequencing. Yeah.
DAN: For synthesis. Yeah. Yeah, these things are very, very repetitive. And those domains are very, very similar to one another. And so when you synthesize DNA, you have to use, you know, a DNA synthesizer that makes smaller pieces of DNA. And then you use many small pieces of DNA that all stick to each other in certain ways to get sort of built up from that. And so if you’ve got these repetitive sequences, then the DNA gets all jumbled and they get all confused, and you can’t really synthesize the thing that you’re trying to synthesize. So, that can be really, really tough.
We need more synthetic biology technology, probably, to really be able to access some of the more complex secondary metabolism systems. I’ll also say that we don’t always know the intimate details, biochemically, of what’s happening. So you know, it’s easy to conceptualize these little domains when you’ve got them, you know, strung out on a piece of paper. So it looks very clear. But biology is not that clean. And so each of those little domains is a little blob of protein that’s, you know, wiggling around in the water. And they all come together into this larger structure that we still don’t really know a whole lot about.
So, understanding the dynamics of this system is complex. So, one of the great things that people thought would be really critical to these and has been a big driver for understanding this is if you’ve got this assembly line and say, you know, you wanted to make a car that had a, you know, different kind of a door, you just take out the part that makes that part of the door. Yeah, you stick that on, in an assembly line analogy. But it turns out that’s really difficult to do because this assembly line, in particular, has evolved over, you know, probably – possibly billions of years. And so it is pretty used to the way that the assembly line is working.
And so just our kind of blind way of pulling a piece out that we recognize and sticking another piece in, that usually doesn’t work, or if it does work, it doesn’t work as well, and so you produce much less molecule than you were before because you’ve done something to slow the process down. Like, you know, your, I don’t know, your assembly line is maybe not quite aligned, right. And somebody’s got to walk over to the corner and grab something to bring in. So you slowed everything down by introducing these foreign components. Because we still don’t quite understand the bigger picture of what’s going on. We’re really just basing this on DNA and not actually on the structure of the protein that you’re engineering… Yeah, the complete system.
So there’s more to do to understand the systems and the dynamics of the biochemistry that’s happening on a protein level. We also don’t quite always know how these evolve. We have lots and lots of biosynthetic gene clusters. But we don’t always have the connections between them. You can imagine an analogy to a fossil record. You know, that we’re missing some of the missing links, right? We don’t always see the connections between one system and another system. There should be. I mean, there’s some evolution that happened. But, you know, bacteria don’t leave good fossil records. So we’re reliant on sequencing organisms that are actually alive and exist. We don’t have – we can’t go back, you know, millions of years to find the precursor sequences. Those species are long dead. And if the DNA sequences have been carried through exactly the way it was, which it almost certainly hasn’t, then we’ve – we have no ability to see the connections in the fossil record. So we don’t, still, have a good idea of how these systems evolve.
ALISON: And we want to be able to better understand how these particular secondary metabolites arose in evolution?
DAN: Yeah, I think the important driver is to imagine if — let’s say you knew you had a molecule. And you knew that if you made this change, which might be a small change, might be a big change. If you could make this change to the pathway, then you could make a molecule that worked better as a medicine or who knows, for whatever reason. “Better” in terms of, you know, utility for some reason. And so the promise of understanding biosynthesis is that you would maybe be able to make that alteration to an existing pathway to produce a molecule that you want, that we would be able to do really complicated synthesis using biological systems.
You know, if we had had the fungus that was making the Taxol rather than the tree – if we had found that first – it would have been much easier to actually have Taxol and not have it be a really expensive drug. So that’s been the promise, is that we can see these systems, we can see how they work, we can’t always see how to make the changes to make them do whatever we want them to do. And that would be really useful in a lot of ways in terms of, you know, just being able to harness nature to do complicated chemical reactions for us.
ALISON: And if we understood the evolution of these biosynthetic gene clusters better then we might be able to engineer them in the ways that we want.
DAN: Exactly.
ALISON: So given those challenges, like, where do we go from here? I mean, I know a lot of sequencing is needed to be able to map that evolutionary tree to better understand these pathways and how they produce these amazing products. But what else and what can everybody do?
DAN: Well, I’m glad you asked. So the JGI has as part of its five-year plan… The JGI comes out with plans for itself over time –
ALISON: Like any good organization does!
DAN: Like any good organization does, and we expect to be around for a long time. And so we want to think about what are the important things that the JGI could be doing for the future. And so, the JGI has decided that secondary metabolism is an important strategic thrust. We think by exploring more aspects of secondary metabolism within our organization, we can develop new technology and drive different parts of the organization to do better science.
The JGI is working on lots of different aspects – or intends to work on lots of different aspects – of secondary metabolism. We have drivers to find more biosynthetic gene clusters and we would do that by sequencing more things, and more things that we know produce secondary metabolites that would be of interest. We want to do more with predicting the products of all of these biosynthetic gene clusters that we’ve already sequenced. So, you know, I’ve got a large database of millions of different biosynthetic gene clusters. But we don’t always know what the end points of the chemistry are. We can make some guesses, but we’ll have to do some technology development to try to improve that. Like we talked about, some of these things are very repetitive. And so that makes actually just the sequencing in the first place, difficult to do.
So if we can make more technology, if we can improve technology, for assembly and cloning and expression, we should be able to actually make the chemical products of some of these biosynthetic clusters that we’re interested in, characterize what those molecules actually are, and then what their function might be. Whether that’s in nature, or whether there’s some utility for humans in any other ways. That’s what we intend to do. But in order to do that, we need partners. And so the Secondary Metabolites Science Program is three people! We’ll use a lot of the technology that already exists within the organization in terms of the sequencing and the metabolomics, synthetic biology. But we need people from outside of the JGI to come to us with projects that will help us actually drive this strategic thrust that we’re interested in doing. So we need the community.
And one of the other great things about secondary metabolism, that I’ve always loved about the field, is that it involves all aspects of biology. You know, I’ve personally been able to work in genomics, in protein structure, in synthetic biology, synthetic chemistry, molecular biology. So anybody could get involved in this field. Anybody who works in some kind of biological research has the opportunity to, you know, use that research towards secondary metabolism aims. And we need new people – we need new people from outside the field to come to us with new technologies and new kinds of ideas about research that maybe hasn’t been done in secondary metabolism before. And that drives the field forward.
DAN: So what we’re going to be doing with this podcast then is try to find those people in the community – people that we already work with at the JGI in terms of projects that the JGI already has underway, and also find, you know, the good scientists in the field that we know of and talk to them about what they think the field needs and what they’ve done in the past and maybe what JGI can do to help drive secondary metabolism as a field forward and do more good science.
ALISON: Yeah, it’s an ambitious vision, you know, driving a whole field. But I think you’re already doing it. You know, with me, I see, just in our discussion today, how interesting and vital secondary metabolites are, and it’s such a pleasure to be here and be able to discuss this incredible, natural diversity that we have at our fingertips. So I’m very excited to learn more and hear more about what JGI and collaborators are discovering.
DAN: Alright, well, I’m glad you’re on board, Alison. Hope we can keep you entertained!
ALISON: Yeah, Yeah, me too. I’m sure you will.
—
DAN: I’m Dan Udwary, and you’ve been listening to Natural Prodcast, a podcast produced by the US Department of Energy Joint Genome Institute, a DOE Office of Science User Facility located at Lawrence Berkeley National Lab. You can find links to transcripts, more information on this episode, and our other episodes at naturalprodcast.com
Special thanks, as always, to my co-host, Alison Takemura. <woohoo> If you like Alison, and want to hear more science from her, check out her podcast, Genome Insider. She talks to lots of great scientists outside of secondary metabolism, and if you like what we’re doing here, you’ll probably enjoy Genome Insider too. So, check it out.
My intro and outro music are by Jahzzar.
Please help spread the word by leaving a review of Natural Prodcast on Apple podcasts, Google, Spotify, or wherever you got the podcast. If you have a question, or want to give us feedback, tweet us @JGI, or to me @danudwary. If you want to record and send us a question that we might play on air, email us at jgi-comms@lbl.gov .
And because we’re a User Facility, if you’re interested in partnering with us, we want to hear from you! We have projects in genome sequencing, DNA synthesis, transcriptomics, metabolomics, and natural products in plants, fungi, and microorganisms. If you want to collaborate, let us know! Find out more at jgi.doe.gov/user-programs.
Thanks, and see you next time!